Key Takeaways (or TL;DR)
- Multimodal AI combines multiple data formats, such as text, audio, video, and images, to deliver more accurate and contextual insights.
- A multimodal AI system follows a six-stage pipeline, including data collection, feature extraction, multimodal fusion, model training, real-time inference, and continuous learning.
- Integrating multimodal intelligence helps businesses reduce operational complexity, boost decision-making precision, automate high-value workflows, and elevate customer experiences.
- Multimodal AI applications span healthcare, automotive, media, finance, and more, creating measurable business ROI and competitive differentiation.
- Some popular examples of multimodal AI models include CLIP, GPT-4V, and DALL-E.
- Adopting AI in a multimodal setting poses several challenges, including data privacy, ethical considerations, and integration complexity.
- Businesses embracing multimodal AI early will gain major advantages in automation, product innovation, and long-term digital transformation.
In today’s fast-changing tech world, businesses are looking for a technology that can manage more than just one type of information at a time. Many systems today can only process either text, images, or numbers, but the real world is much more complex. To effectively handle and work with various types of information, multimodal AI has been developed.
Using AI-powered multimodal tools enables businesses to interpret several data formats simultaneously, just like humans use multiple senses at once. This gives your business a deeper understanding of customer behavior, operational patterns, and risk signals, helping you act faster and with greater precision.
If your goal is to improve accuracy, personalize customer experiences, or automate complex workflows, these AI systems provide a practical pathway to get there. Through this guide, you will understand what multimodal AI is, how it works, where it drives ROI, and how your business can adopt it effectively.
What is Multimodal AI? Understanding Why Businesses Are Adopting It Over Unimodal AI
Multimodal AI is an advanced form of AI that can process and interpret multiple data formats, such as text, images, audio, video, and sensor inputs. It uses technologies like deep learning, specialized encoders (transformers, CNN), computer vision, speech recognition, and fusion mechanisms to generate more accurate, context-rich insights.
Unlike unimodal models, which rely on a single source of information, multimodal systems combine these diverse inputs to build a more complete understanding of real-world scenarios.
Businesses can leverage these AI capabilities to analyze customer feedback across text & voice, optimize operations using video and sensor data, or enhance diagnostics by combining medical images with clinical records. This technology bridges information gaps and provides a holistic view, enabling predictive, data-driven strategies.
The global market for multimodal AI is projected to grow at a CAGR of 36.8% from 2025 to 2030, highlighting how businesses are rapidly moving towards more integrated intelligence.
To better illustrate this shift, we have prepared a comparison table that provides a closer look at the core differences between Multimodal AI and Unimodal AI.
| Core Differentiation Between Multimodal AI vs. Unimodal AI | ||
|---|---|---|
| Features | Multimodal AI | Unimodal AI |
| Data Inputs | It processes multiple data types simultaneously, including text, images, audio, and video. | It can proceed only with a single data type. That is, it either works with text, images, or audio, but not all three together. |
| Contextual Understanding | Provides multi-dimensional, actionable insights. | Limited to one-dimensional analysis. |
| Accuracy | Higher accuracy by cross-referencing multiple sources. | Depends on the quality of a single data source |
| Example | Generating an accurate diagnosis report by combining medical images, reports, and patients’ speech. | It primarily responds to text queries via AI-powered chatbots. |
How Do Multimodal AI Systems Work?
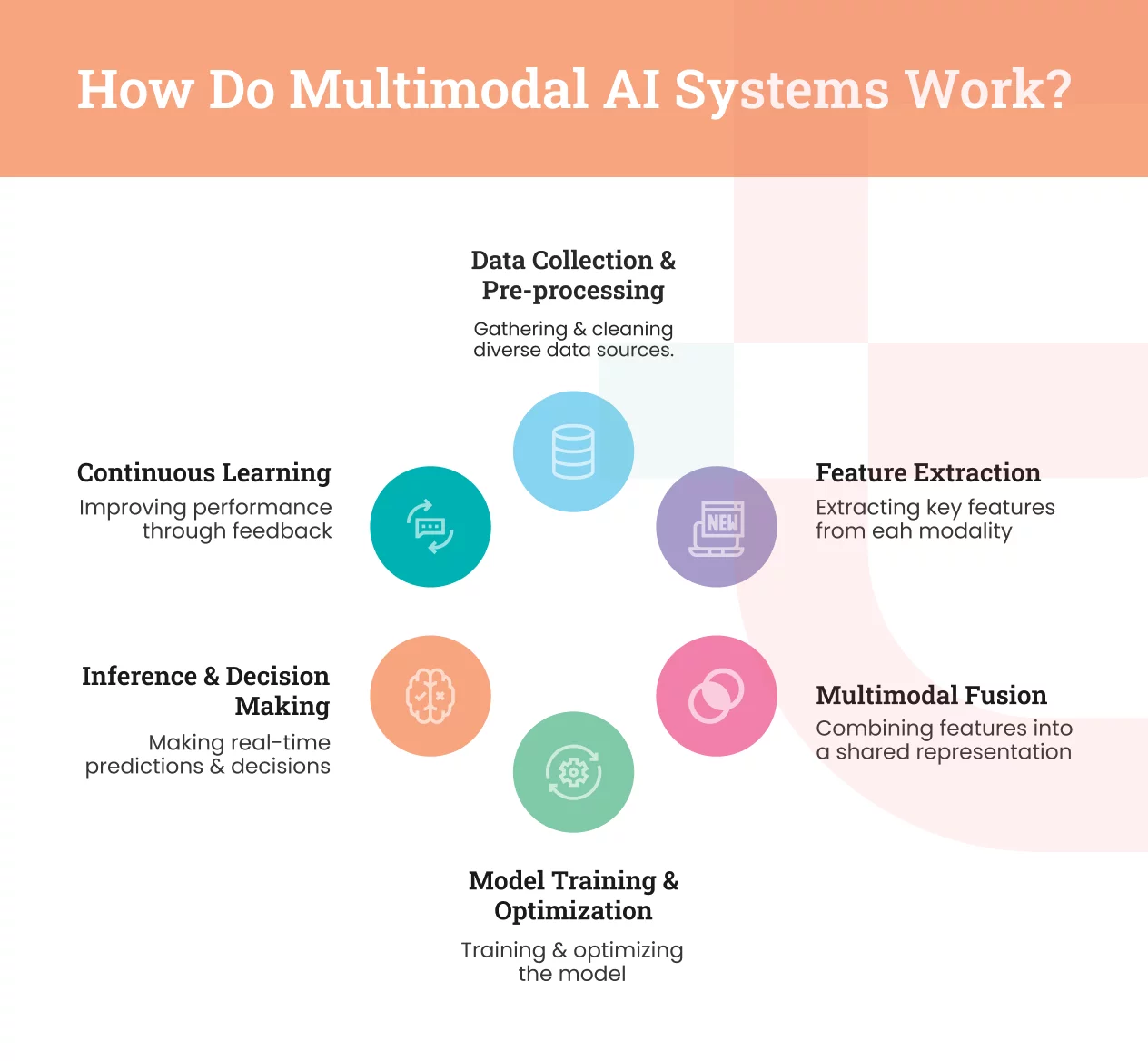
Multimodality is not just about “data input from multiple sources.” It is a structured pipeline that collects, transforms, merges, and learns from diverse data formats and operates continuously to improve the model in real time.
Below, we provide a clear breakdown of each stage that enables your multimodal AI system to be successfully implemented in your solution.
Data Collection & Preprocessing:
This is where your multimodal AI journey begins! This stage helps you gather data from multiple channels, including text, audio, images, voices, and IoT devices, to prepare everything that works cohesively.
Following the accurate collection of data, preprocessing is conducted to standardize and align all data formats for optimal machine utilization, which includes:
- Remove errors & duplication in data,
- Keep the format simplified across modalities.
- Log audio, video, and events whenever necessary.
Moreover, leveraging AI-powered data visualization during this phase can significantly accelerate processing time while simplifying the detection of complex patterns and anomalies. This ensures an error-free setup for this foundational stage.
Feature Extraction:
Once the raw data is refined, the multimodal AI model extracts meaningful features from each modality independently. Through this stage, it enables your system to identify the specific insights that drive business value from each data type, such as:
- Detecting sentiment, or intent, in text.
- Identifying objects, patterns, or attributes in images.
- Recognizing emotions or tone in voice or audio.
This enables each modality to contribute depth, thereby providing the system with a richer contextual foundation before fusion.
Multimodal Fusion & Representation Learning
This stage makes your multimodal AI more powerful than that of the unimodal architecture. Fusion merges modality-specific features such as text, images, and audio to build a unified understanding, enabling deeper context and more accurate decision-making for businesses.
| Fusion Type | How It Works |
|---|---|
| Early Fusion | It combines the raw features at the beginning of the pipeline. |
| Late Fusion | Processes each modality independently using separate models, then combines them for the final outputs. |
| Hybrid Fusion | It implements multi-stage, layered integration using attention mechanisms or transformer-based architectures. |
Model Training & Optimization
Next, your system undergoes intensive training using comprehensive multimodal datasets, with iterative optimization that enhances accuracy, minimizes error rates, and ensures consistent performance under real-world business conditions.
Simply put, this stage helps you determine how smart, scalable, and reliable your multimodal performance is in a production environment.
After training, model optimization is essential. Therefore, below are some of the effective model optimization strategies that you must consider:
- Hyperparameter tuning
- Reducing overfitting in multimodal datasets
- Enhancing cross-modal attention precision
- Optimize inference speed
- Modality balance
This training phase transforms your system from basic pattern recognition to data-driven decision-making, delivering measurable ROI in enterprise environments.
Inference & Real-Time Decision Making:
Considered as one of the core stages, where your multimodal AI system shifts from training mode to business deployment, delivering the value you have invested in. Once deployed, your system processes new data from multiple sources in real-time to make accurate decisions and predictions.
Whether it’s an AI agent handling customer conversations or an Internet of Things (IoT) system responding to environmental changes, these steps drive real-world impact.
Continuous Learning & Model Improvement:
An AI system doesn’t stay static after deployment; it constantly adapts and improves in response to changes in customer preferences and conditions. This process ensures that your AI investment delivers increasing value over time rather than becoming outdated.
Now, let’s have a closer look at how your system evolves:
- Adapting to changing business requirements.
- Enhances predictive accuracy
- Minimize the biases
- Improves customer experience by delivering personalized services
- Incorporate data that aligns with emerging AI trends.
Collaborate With Elluminati to Build a Multimodal AI System for Your Business – Enhanced Decision Making by Combining Text & Images
Exponential Benefits of Implementing Multimodal Artificial Intelligence in Modern Business
The strategic value of multimodal AI extends far beyond incremental improvements. Businesses are deploying this system, resulting in transformational outcomes across their key performance indicators. Let’s dive into some compelling ways AI impacts business.
Enhanced Decision Making
A multimodal AI model combines inputs from text, audio, video, sensor data, and structured logs to generate highly accurate insights based on real-world context. This allows you to make an informed business decision by minimizing human errors while eliminating data inaccuracies.
Cost Efficiency in Operations
One of the compelling benefits of an AI-powered multimodal system is its cost efficiency. By automating workflows that previously required human interpretation, the AI system now handles them solely, resulting in significantly reduced operational expenses while also accelerating overall output.
Cost Value-add is most evident in:
- Replacing manual data review with access to images, documents, and calls.
- Minimizing support hours with the help of AI agents & other assistant tools.
- Eliminates the redundancies across departments using shared multimodal pipelines.
Improved User Interaction
Nowadays, customers expect natural, intuitive experiences when shopping or exploring products on online platforms, and that is where multimodal AI models come into play. By processing voice commands, gestures, and visual inputs simultaneously, it enables seamless interactions with your customers without human intervention.
Some of the key examples of these include:
- AI chat interfaces that understand customer tone, buying patterns, and more.
- Virtual assistants that can process voice, screenshots, and instructions together to understand what the customer is looking for.
- Personalized recommendations by combining the behavioral & contextual signals.
Automation of Complex Tasks
Unlike unimodal AI, which handles repetitive tasks but struggles to deliver precise outputs due to mixed data. At the same time, multimodal AI models change that by enabling automation previously only possible with human review.
Whether it is identifying product issues from customer conversations to medical diagnoses using written reports and patient history, this system empowers you to scale without proportionately increasing your manpower.
Predictive Accuracy
By combining signals across data sources, multimodal AI delivers significantly higher prediction accuracy than that of the outdated system. Below are some of the improvements that you will determine in your business by incorporating this advanced AI capability:
- It surpasses the demand forecasting
- Predict the equipment maintenance in advance, saving you from last-minute expenses.
- Greater accuracy in customer churn analysis
In fact, accuracy at scale becomes even more powerful when used along with a predictive analytics tool.
Real-Time Contextual Understanding
From recognizing objective to voice commands, text, and behavior, a multimodal system does not simply produce outcomes faster; it interprets changes in real time. This real-time reasoning enables intervention, mitigation, and decision-making without human delay.
Moreover, it opens a space for human-augmented technology, where AI complements rather than replaces workforce capabilities.
Scalable Data Handling
As your business grows, multimodal AI models scale effortlessly to handle increasing data volumes across multiple formats. This flexibility future-proofs your AI investments, allowing you to expand capabilities without rebuilding infrastructures.
Core scalability benefits include:
- Unified frameworks that easily process text, video, audio, and IoT sensor data in one system.
- Cost-effective growth for business by eliminating the need to invest in infrastructure while integrating AI services in business.
- Maintaining response times even as data volume multiplies.
- It scales easily across cloud infrastructure as your needs evolve.
Top 6 Multimodal AI Applications Across Industries
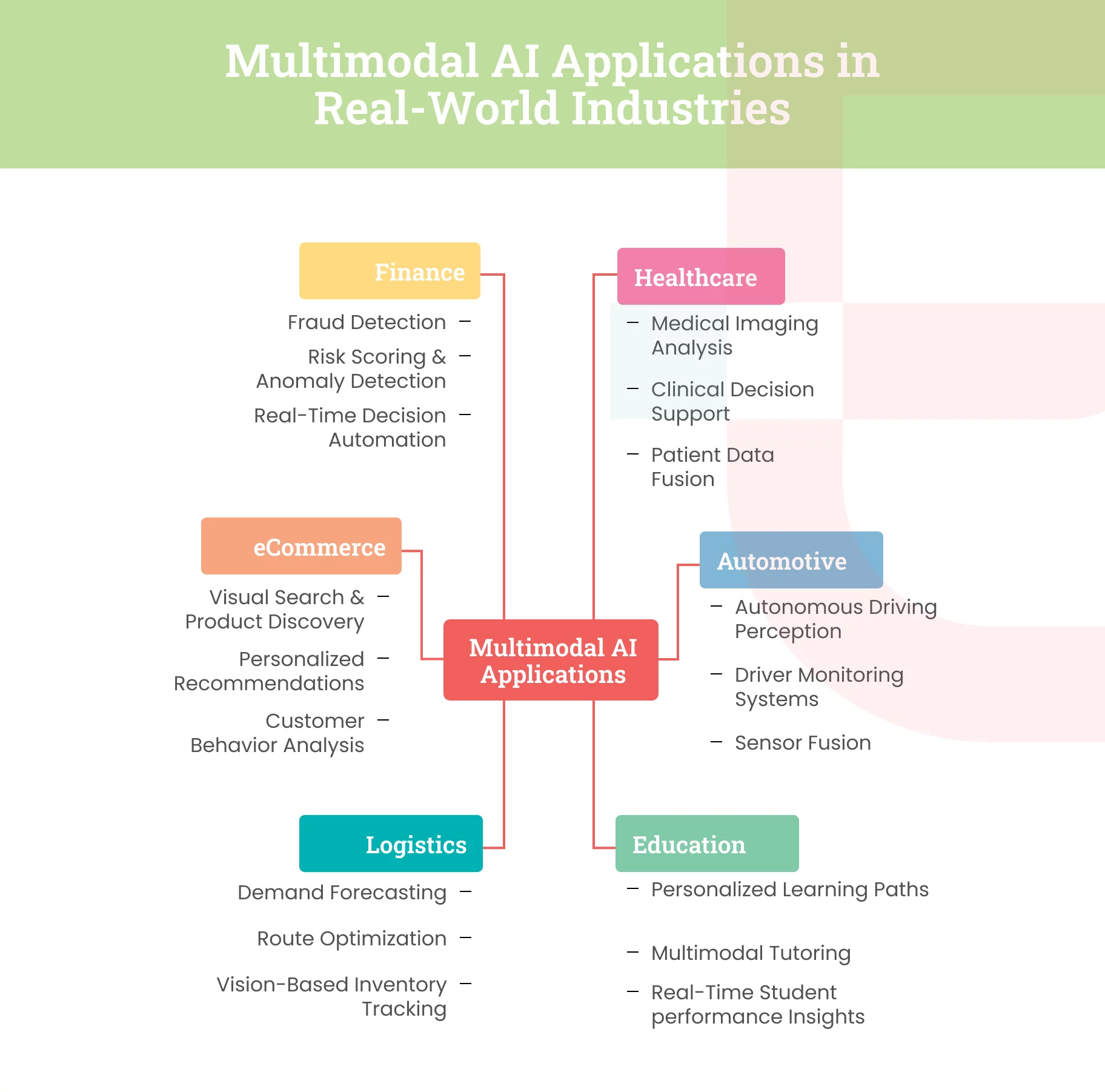
Healthcare
In this rapidly evolving healthcare landscape, businesses are leveraging advanced technologies to enhance patients’ outcomes and operational efficiency. One such transformative technology is multimodal AI. It integrates diverse data sources, including medical images, EHRs, lab results, and real-time patient monitoring, to enable a comprehensive understanding of each patient’s condition.
In fact, businesses are increasingly adopting AI in healthcare, which is projected to grow significantly from $3.43 billion in 2026 to $42.8 billion by 2034; this growth underscores the increasing reliance of healthcare businesses on AI-driven solutions to remain competitive & improve patient care standards.
Automotive
The automotive sector is entering a new era of multimodal AI, which merges data from cameras, LiDAR, radar, GPS, and ultrasonic sensors to support autonomous navigation. Vehicles can interpret their surroundings, respond to voice commands, and adapt to changing road situations, improving both safety and customer experiences.
Beyond driving, AI in the automotive industry also helps businesses streamline production. A multimodal AI system analyzes visual feeds, acoustic signals, and equipment metrics to detect quality issues early, reduce waste, and shorten development cycles through automated testing & validation.
Education & Adaptive Learning Platforms
By integrating data from various sources, such as text, video, and interactive content, multimodal AI applications enhance educational learning opportunities. Customizing instructional materials and incorporating AI-powered virtual reality enables the delivery of a personalized learning experience for students while fostering greater engagement.
Moreover, smart learning systems interpret facial expressions, response patterns, and behavior trends to recommend suitable materials. Students struggling with text may receive visuals, simulations, or interactive exercises to improve comprehension and reduce learning gaps.
Logistics & Supply Chain
Multimodal AI enhances logistics by combining data from IoT devices, GPS, warehouse cameras, and weather insights to streamline operational decisions. Automated systems can navigate warehouses, manage product placement, and maintain safety using real-time spatial awareness.
Route optimization tools evaluate traffic, weather, and historical patterns to recommend efficient delivery paths. Meanwhile, predictive maintenance uses user sensor data to prevent fleet breakdowns, and the inventory system uses visual and demand cues to maintain accurate stock levels.
eCommerce
In the eCommerce sector, multimodal AI improves the customer experience by combining data from user interactions, product visuals, and customer reviews. By analyzing purchase patterns, browsing habits, voice interaction, and emotional cues, it delivers customers with personalized customer experiences.
Moreover, tools such as virtual try-ons and visual search deepen product engagement by enabling customers to preview items or find similar products instantly. Sentiment insights from reviews and social activity help you refine offerings and improve customer satisfaction.
Financial Fraud Detection & Risk Management
Did you know that businesses are increasingly adopting AI in the finance market, resulting in reaching USD 190.33 Bn by 2030?
Incorporating multimodal intelligence into the finance sector enables you to examine transaction behavior, device data, biometrics, and location patterns simultaneously. This improves fraud detection accuracy and blocks threats before transactions proceed.
An advanced system evaluates behavioral signals, such as typing rhythm and navigation pattern, alongside financial history. Moreover, this Multimodal also helps analyze and strengthen credit scoring and anti-money laundering by comparing diverse data sources in real time.
Ready to Implement Multimodal AI in Your Business? Share Your Industry-Specific Needs, and We’ll Help You Design a Tailored System
Discover the Leading Examples of Multimodal AI Models in 2026
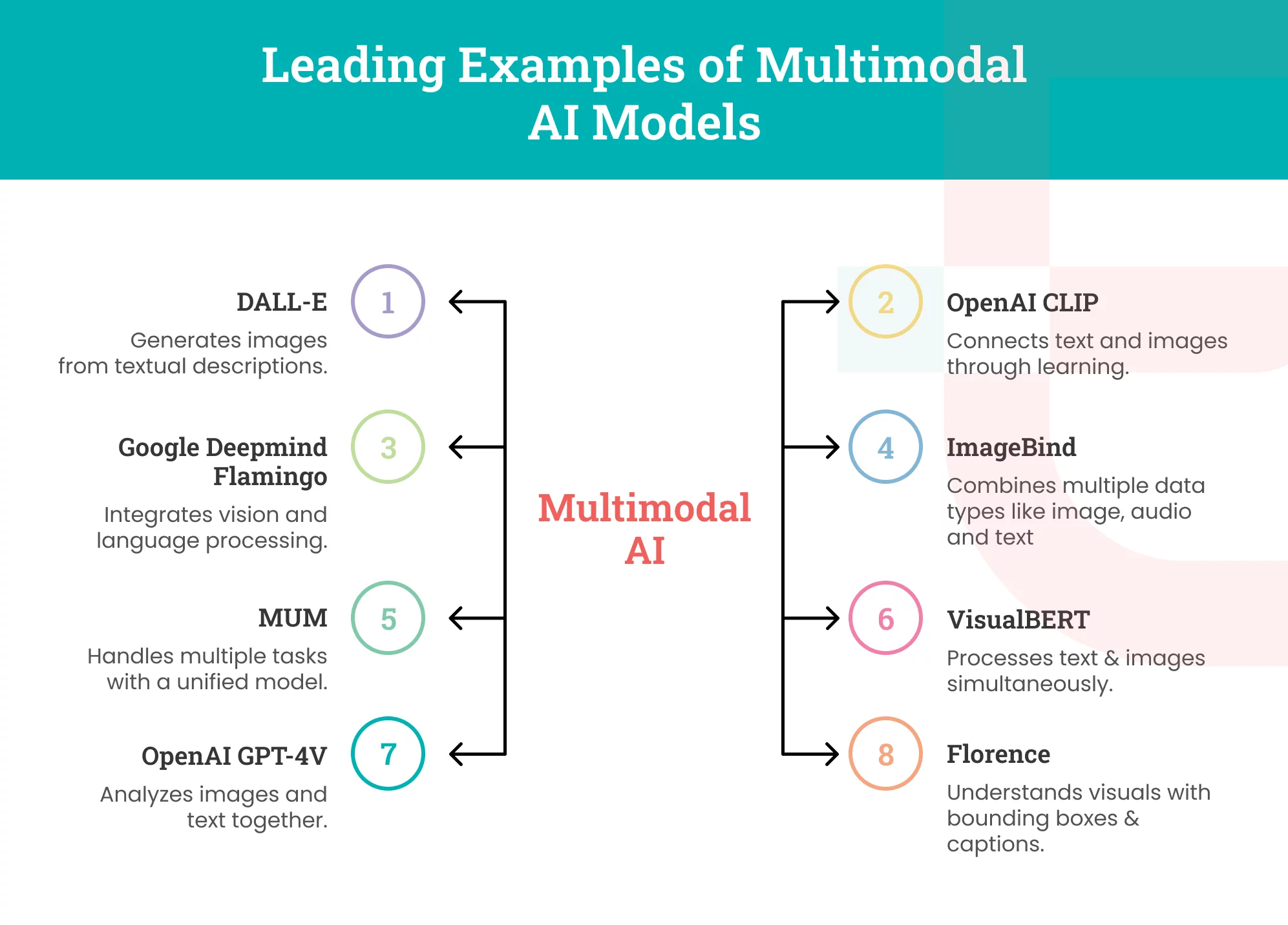
Modern multimodal AI models enable enterprises to analyze information from multiple sources simultaneously, enabling faster, more informed decision-making. Their ability to blend visual, textual, and audio data unlocks deeper context and more relevant outputs.
Below are some leading examples of AI models driving innovation and real-world impact across sectors.
DALL-E
DALL-E is OpenAI’s generative model that turns written descriptions into highly detailed & original images. It transforms written ideas into visual outputs. By fusing language understanding and image generation, it empowers designers, marketers, and content creators to prototype, visualize, and iterate rapidly.
OpenAI CLIP (Contrastive Language-Image Pretraining)
OpenAI’s CLIP aligns images and text by learning from large-scale image-caption pairs, enabling powerful zero-shot classification. Its contrastive architecture lets it understand visual content using natural language, making it widely used in vision-language retrieval and classification tasks.
Google DeepMind Flamingo
DeepMind’s Flamingo is an advanced multimodal model designed for image-text understanding. It can generate captions, answer questions about images, and analyze visual content by interpreting text and images together. Businesses adopt Flamingo for domain-specific scenarios where labeled data is limited or costly.
ImageBind
Developed by Meta AI, this is a powerful multimodal AI capable of handling data in invariant modalities, including text, images, audio, video, thermal, and depth. It can also generate outputs in these modalities while understanding the multi-faceted information.
MUM (Multitask Unified Model)
Developed by Google, MUM (Multitask Unified Model) is engineered to address complex queries by integrating various modalities, such as text and images. It is designed to understand and generate insights across languages and handle cross-lingual tasks. It improves search and information retrieval by offering more detailed and cohesive responses through its ability to merge data from diverse modalities.
VisualBERT
VisualBERT combines visual features with BERT’s language representations to jointly understand text and images. It enhances multimodal reasoning for tasks such as image captioning and visual question answering by integrating visual and textual context.
OpenAI GPT-4V (Vision)
OpenAI GPT-4V extends GPT-4 with powerful vision understanding, allowing it to interpret images and generate text-based responses. It supports tasks such as image explanation, object recognition, and data extraction, combining visual reasoning with natural-language fluency.
Florence
Florence is Microsoft’s advanced vision-language model that combines image and text data for tasks such as image retrieval, visual reasoning, and content classification. Its multimodal design enhances understanding by integrating visual and textual context, enabling more precise and context-aware analysis.
Explore the Key Challenges of Multimodal AI & Solutions to Overcome Them
While the potential of multimodal AI is transformative, businesses must overcome several practical and technical hurdles. So, let’s understand these challenges and uncover their strategic solutions that help businesses accelerate adoption and achieve measurable ROI.
Data Privacy & Security
Multimodal AI requires handling diverse, often highly sensitive data, from biometric recordings to medical scans. This creates higher risks of privacy breaches and cybersecurity threats. Also, when handling multiple datasets, it is difficult for businesses to comply with regulations such as GDPR and HIPAA.
Strategic Solution:
- Incorporate a secure & advanced framework including encryption, access controls, and continuous auditing.
- Leverage federated learning to train models without centralized sensitive data.
- Establishing a unified data governance & consent management system to ensure compliance across all modalities.
Integration Complexity
Many businesses rely on outdated or fragmented systems with inconsistent formats and siloed data. Therefore, integrating multimodal AI into these environments requires extensive engineering and often increases the chances of disrupting the existing workflows.
Strategic Solution:
- Adopt API-first designs & standardized interfaces to make the system easier to connect to.
- Collaborate with a trusted AI development firm to get streamlined AI integration services.
- Implement modular architecture, as it adds capabilities progressively without complete replacements.
Computational Complexity & Scalability
Multimodal models, especially large transformer-based architectures, demand high computational power. Training and running those models can be expensive, particularly for small- or medium-sized businesses that don’t have advanced hardware or infrastructure.
Strategic Solution:
- Fine-tuning the existing model rather than training new ones from scratch can significantly reduce computing costs. Useful model optimization methods to reduce inference costs while maintaining a high level of accuracy.
- Leverage a model-as-a-service platform to avoid paying for unnecessary infrastructure.
Data Fusion & Quality Assurance
Each data type, including video, audio, text, and IoT signals, has different formats and quality levels. Misalignment leads to inaccurate fusion and degraded model performance.
Strategic Solution:
- Develop a robust preprocessing pipeline that automatically cleans, aligns, and simplifies data across modalities.
- Leverage an attention-based fusion approach to understand how different modalities relate to each other.
- Implement a dedicated quality check for each data type & track integrity.
Ethical & Privacy Concerns
Multimodal artificial intelligence can unintentionally reinforce biases present in training data. Their complexity can also make it difficult to explain why certain predictions were made, especially in high-risk fields like healthcare or finance.
Strategic Solution:
- Conduct bias and fairness evaluations across different demographic groups before deploying models.
- Utilize advanced tools & frameworks to clarify how each modality influences outcomes.
- Keep human review and oversight in high-stakes decision-making, supported by internal ethical review boards.
How Can Elluminati Help You Build a Multimodal AI for Your Business
Multimodal AI marks a major shift in how businesses process information by combining text, images, audio, and video into unified intelligent systems. It offers deeper context, higher accuracy, and superior user experience, making it a fast-growing essential for innovation. Now, to help you harness this potential, Elluminati offers a customized multimodal system aligned with your goal.
Our team has a deep understanding of technologies such as ML, computer vision, and NLP, and they implement them effectively to build scalable systems that integrate seamlessly with your workflows. By partnering with Elluminati, your trusted AI development company, we help you accelerate your digital transformation with proven multimodal AI implementations.
FAQs
Multimodal AI combines data from multiple sources, such as text, images, audio, and sensor inputs, into a single system. This integration allows AI models to analyze diverse data types simultaneously, improving decision-making and automation accuracy.
Multimodal AI differs from traditional AI approaches in its ability to handle and integrate multiple data types simultaneously, including text, images, audio, and video. Whereas traditional AI models, often called unimodal, focus on a single type of data, such as text or images.
Here are some of the compelling benefits that a multimodal AI can deliver to businesses, including:
- Enhancing performance across complex tasks
- Improving user experience
- Scalability across various industries
- Versatility in real-world applications
The cost of building an AI ranges from $20K-$50 for basic MVPs to $200K+ for advanced, enterprise-grade systems. However, several factors influence the cost, including the expertise required, the complexity of integration, model training, and other customized needs. To obtain an accurate quotation, we recommend contacting our sales executive team at sales@elluminatiinc.com.
By integrating diverse data types, a multimodal AI system captures more context and complexity, reducing errors and enhancing the precision of its outputs compared to single-mode models that rely on a single data source.
There are three main components of multimodal AI, including.
- Input modules for each data type
- Fusion modules that combine data, and
- Output modules that generate responses
The following are some of the significant challenges that a business often faces when implementing multimodal artificial intelligence in its business, including:
- Data privacy & security
- Ethical concerns
- Integration complexity
- Data fusion & quality assurance